核心能力
从 PDF 上传到结构化结果,全流程自动化,无需任何人工标注前置工作。
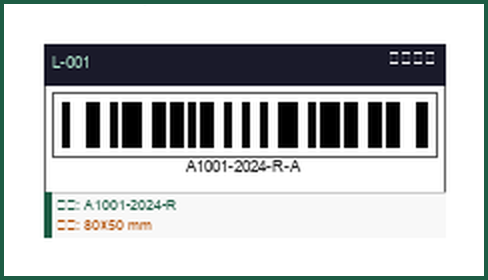
Pass 1 直接解析 PDF XObject 矢量层,无需渲染即可提取嵌入图像并解码; Pass 2 将页面渲染为高分辨率位图,使用干扰线过滤后再由 pyzbar 和 zxingcpp 双引擎解码, 确保印刷模糊或旋转条码也能被识别。
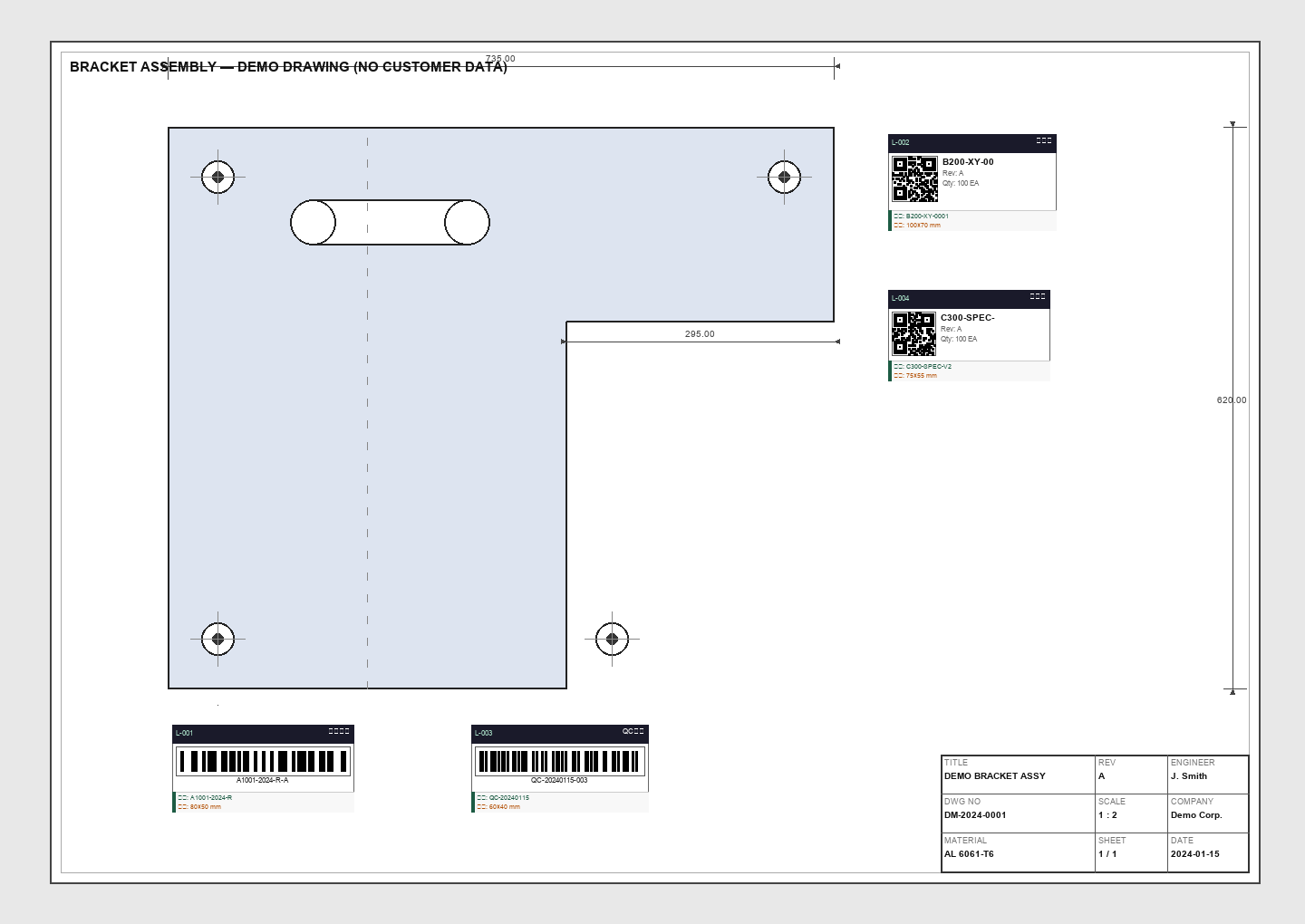
矢量 + 图像双扫描检测到条码后,系统自动将周边的尺寸标注(含公差值)、文字注记、载体信息合并为完整标签组, 输出结构化 JSON:标签名称、贴纸编号、规格参数、扫描样本一应俱全。
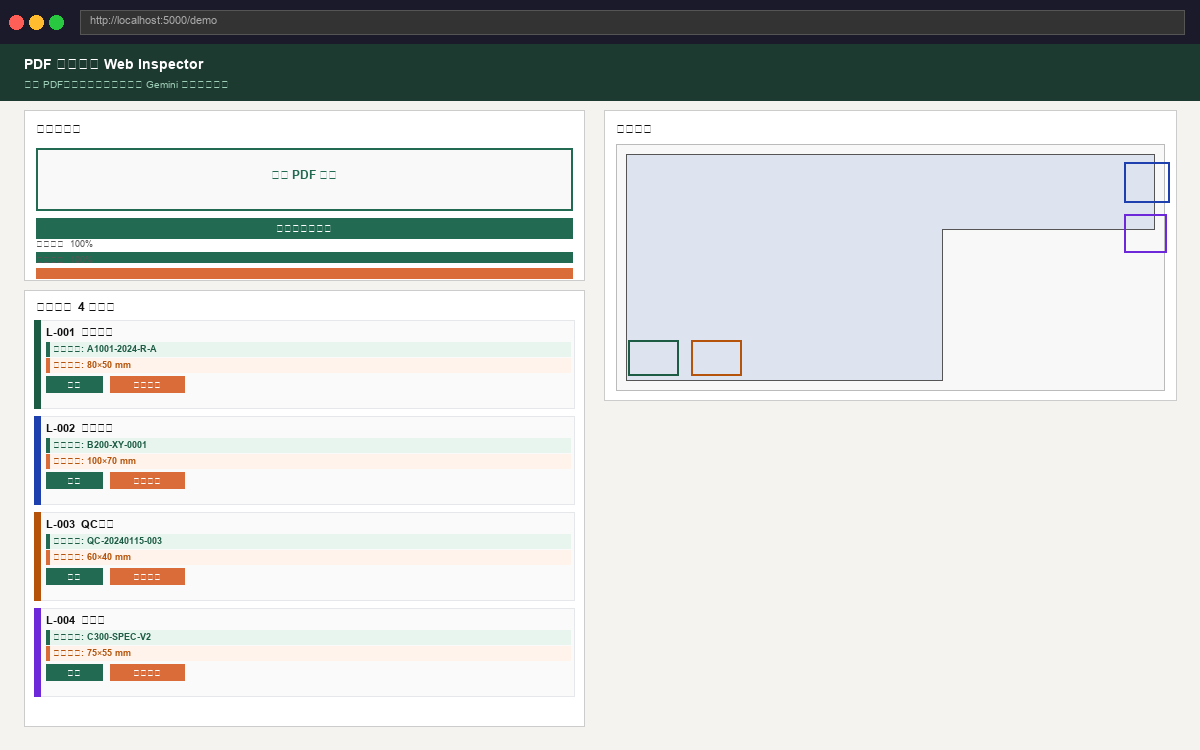
结构化信息提取左侧全页预览图实时叠加彩色标注框与编号标签,右侧卡片列表展示每个标签的缩略图与详细信息; 点击任意卡片或标注框可双向联动高亮,"放大查看"按钮打开 2.8× 高清裁切图。
交互式标注界面配置 Gemini API Key 后,系统自动对置信度低的可疑标签发起 AI 二次确认, 智能补全载体类型、规则说明等缺失字段,仅在必要时调用 API,控制成本。
按需调用,精准复核上传进度与分析进度分别由独立进度条展示,后端推送阶段状态(本地检测 → AI 复核 → 渲染素材), 任务完成后结果页面自动载入,无需手动刷新。
上传 + 分析双进度每次分析结果均以标准 JSON 持久化,包含标签位置坐标(ANNOT_SCALE 坐标系)、 解码字符串、缩略图路径、AI 补全字段,可直接对接下游系统或导出报告。
标准化数据格式工作流程
从上传到结果,整个过程完全自动化,通常在数十秒内完成。
点击选择或拖拽 PDF 文件到上传区,支持任意尺寸的工程图纸, 可勾选是否启用 Gemini AI 复核。文件上传完成后点击"开始分析"即可。
系统并行执行矢量层解析和图像层扫描,对找到的条码进行聚类, 提取关联文字和尺寸,按需调用 Gemini 对可疑结果复核。全程进度实时可见。
分析完成后页面自动展示:左侧图纸全页图叠加彩色标注框,右侧标签卡片列表, 支持点击联动定位与高清放大,所有结果可通过 API 获取 JSON 数据。
效果预览
以下效果图基于模拟工程图纸生成,不含任何真实客户信息。
图纸全页标注视图
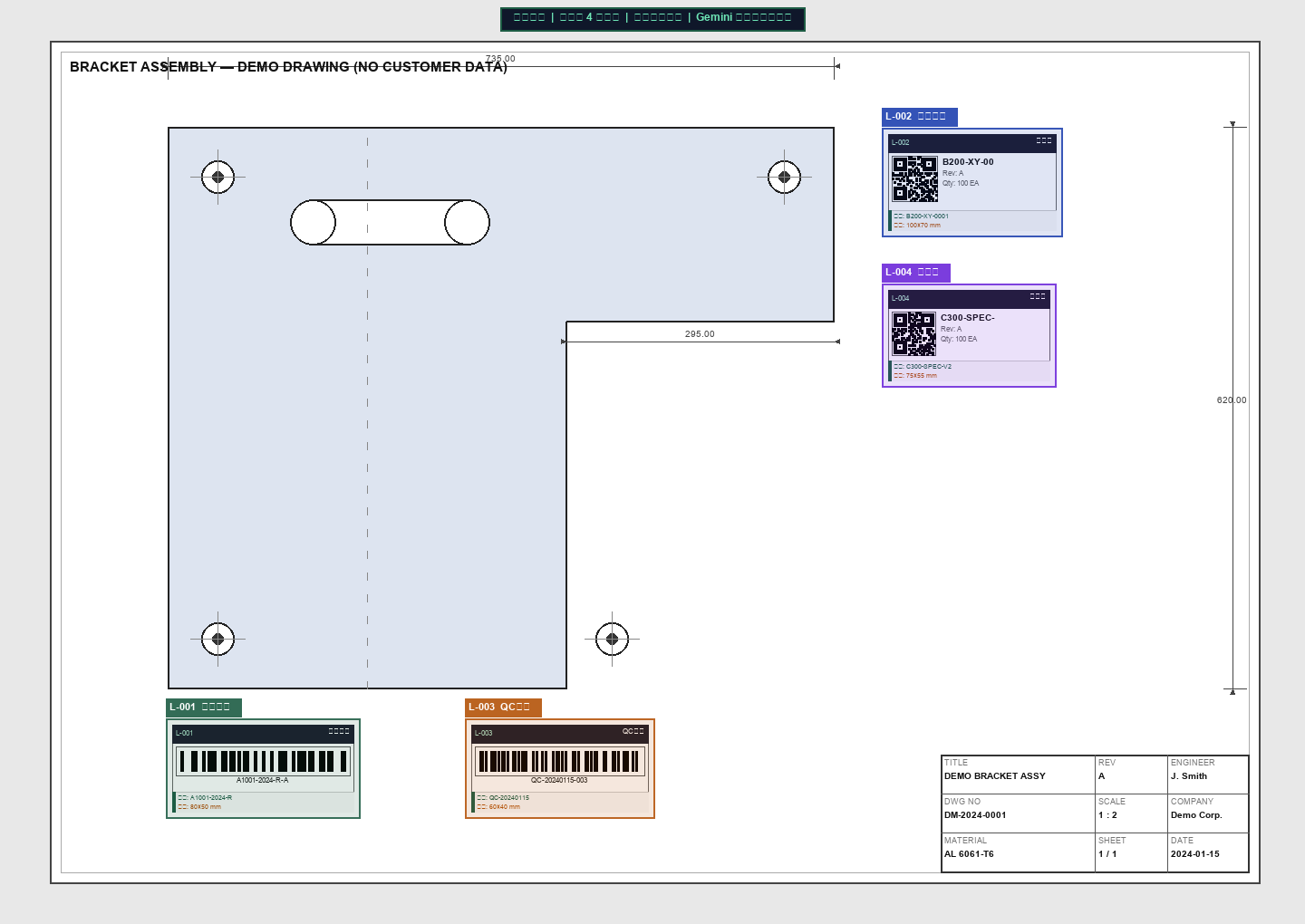
标签详情卡片
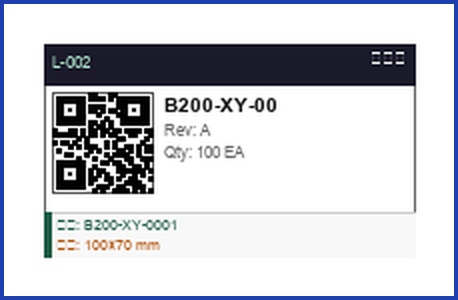
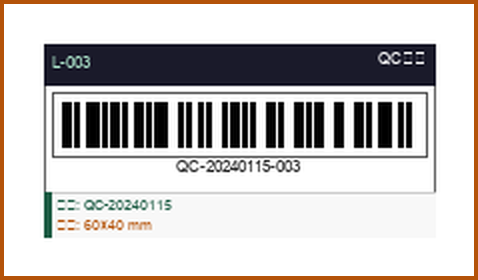
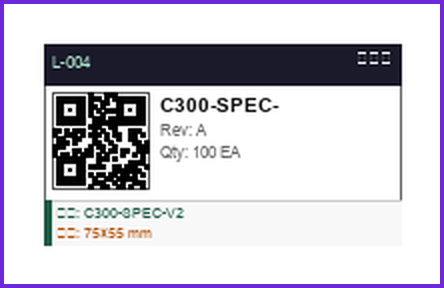
演示界面
上传 PDF 后界面将自动展示检测进度与最终结果,支持交互式查看与导出。